tl;dr → At the 2014 Perl QA hackathon in Lyon, I worked on PAUSE, Module::Metadata, version number semantics, Test::Harness, CPAN.pm, CPAN::Reporter, Dist::Zilla and more.
Why do I love the QA hackathon? 🔗︎
As I mentioned in my TPF grant application, the QA hackathon allows me to work in a concentrated way for several days on parts of the Perl/CPAN toolchain and testing infrastructure that are “too big” for ad hoc development during the year. It also gives me an opportunity for face-to-face collaboration with other toolchain/quality hackers, which means getting answers, insights and making decisions much faster than happens over email, IRC, or ticket trackers.
The QA hackathon is like the best conference “hallway track” mashed up with a coding marathon with some of the most incredibly talented hackers in the Perl community.

What was different? What was the same? What worked? What didn’t? 🔗︎
The big difference this year is that the organizers wisely shrunk the size of the event back to the 30-ish number that had been typical for most of the early years of the hackathon. At that number of attendees, everyone can pretty much know what everyone else is working on and basic logistics take up much less time.
There were several new faces, including Karen Etheridge, Graham (“one-p”) Knop, and Neil Bowers. And there were a lot of familiar faces, including many that I only see once a year at the hackathon.
In addition to the smaller group, I really appreciated how much the organizers optimized for productive time. Breakfast and lunch were provided at the venue, and there was only a single organized dinner out and another organized dinner at the hotel. That meant less time in transit for food and more time to get stuff done.
Sadly, as in some previous years, the network was flaky, both at the hotel and the conference venue, which is always a distraction and occasional barrier to getting work done.
Giving thanks 🔗︎
Before I give the day-by-day recap, I want remind readers that each year, the QA hackathon happens because of the dedicated volunteer work of the organizers and the financial support of sponsors.
I offer many thanks to Philippe Bruhat and Laurent Boivin for putting together an excellent hackathon, to Booking.com for providing our venue, and to Wendy van Dijk for helping each day with critical logistics: ensuring we did not lack for food or drink! I also particularly want to thank the The Perl Foundation for the travel grant that allowed me attend.
All our sponsors deserve great thanks! These companies are putting their money where their mouth is to make the Perl ecosystem better for everyone: Booking.com, SPLIO, Grant Street Group, DYN, Campus Explorer, EVOZON, elasticsearch, Eligo, Mongueurs de Perl, WenZPerl for the Perl6 Community, PROCURA and Made In Love.
If you think the QA hackathon work is valuable for the Perl community, please consider making a late contribution to the hackathon fund to support the 2015 QA Hackathon.
Thank you, also, to my fellow participants. You’re the reason I keep going back.
Day-by-day Recap 🔗︎
I’m going to give a pretty detailed, stream-of-consciousness replay, because I think it will give readers some insight into the frenetic way the QA hackathon tends to work. It’s rare (at least for me) to be working on just one project for very long. Frequently I jumped back and forth between discussions with people and actually coding.
Day 0 🔗︎
Ricardo Signes and I flew together and arrived in Lyon in the afternoon with the usual red-eye flight exhaustion. We met up with Karen and Barbie at the airport for the ride to the hotel. We met up with most of the rest of the hackers that night for drinks and dinner and started to swap ideas about what we might be working on.

Day 1 🔗︎
On Thursday, after introductions and the “stand-up” where we each talked about our plans, I pulled together a bunch of people to talk about PAUSE issues and tasks. One of the big topics was how to implement some of the decisions taken in the Lancaster Consensus the previous year. We also talked about how to get stricter about case-sensitivity, to avoid the “ElasticSearch renaming” problem.
Another related topic was separating assigning permissions from indexing modules, so that someone could get permissions on the namespace of a module while still releasing non-indexed developer versions of it.
Later that day, I summarized all the discussion into a PAUSE distribution permissions and indexing rules document. The big change is that — per Lancaster Consensus — your distribution “name” (the first part of the tarball filename) will need to match a Perl package that you have upload permissions for.
Ricardo and others then went off to implement various parts of this and solve the problem of existing distributions that don’t match a package and I’ll let him/others cover that in other blog posts. (Update: see Ricardo’s blog post)
Next, I talked to Karen and Graham about improving the security of Module::Metadata (which has to evaluate code to determine $VERSION) so that perhaps it could eventually be used by PAUSE. They took some prototype work I already had and started running with it, checking with Christian Walde about how to handle sub-process issues portably to Windows.
At other points during the day, I sent Tim Bunce some ideas for how role-based testing might help DBI testing and helped Jens Rehsack with a warnocked takeover request for some of Adam Kennedy’s modules.
I also took a moment to get everyone’s attention so that I could hand out a special award (only partly in jest) to Peter Rabbitson for his efforts keeping backwards compatibility for Perl 5.6. I called it the Wandering Albatross Award and gave him a stuffed albatross. It was also Peter’s birthday, so I got us to sing to him. He took it all well and the albatross kept him company for the rest of the hackathon.

With all these discussions going on, it wasn’t until after dinner that I got to any of my own coding, but I managed to do a couple cool things before bedtime:
- Revived a patch for Test::Harness to let authors define rules for parallel testing via a file in their distributions (more in Day 2)
- Sent a CPAN.pm pull request with a configuration option to automatically switch on
PERL_MM_USE_DEFAULTfor prompt-free installation.
Day 2 🔗︎
On Friday, I finished my work on a test rules file for Test::Harness and fired off a pull request for it. The problem was that some people are setting parallel testing by default to speed up module installation. This usually works, but some distributions have tests that won’t work in parallel. Fixing a test suite like that is a lot of work, but instead, they’ll be able to add a testrules.yml file that specifies their tests don’t work in parallel and need to be run in series. The rules code for this was always in TAP::Harness, but there was no way for authors to control it short of customizing ExtUtils::MakeMaker or Module::Build. Now there will be.
Jérôme Quelin stopped by to discuss some cpan -O bugs finding outdated modules. There were two cases in which apparently identical versions between the locally-installed module and CPAN were being reported as out of date. One of those turned out to be a bug in the decimal precision of the report and I sent Jerome to file a ticket on App::Cpan. The other turned out to be a bug in how CPAN.pm compared “undef” and “0” and I send Andreas a pull request to fix it.
I then worked on my own pull request backlog for a bit to get things shipped:
- Test::API patches for fewer dependencies and a class-api test
- Term::Title fixes for non-interactive testing
- CPAN::Reporter::Smoker patch to skip dev distributions
All that work got me to dinner time and I went with a small group (Ricardo, Peter, Karen, Graham, and Leon) to have a dinner discussion about various issues and challenges relating to version objects and the toolchain. We decided to momentarily set aside the current state of affairs with respect to version objects and just talk about the different ways that versions are represented in Perl (decimal and tuple forms). We sketched out our ideal semantics and transformations and I wrote it up after we got back to the hotel. (Leon would later do some prototyping on Saturday and Sunday).
We’ll continue the discussion virtually over the next several months and see if it leads to a concrete proposal for how to rationalize version number semantics in perl 5.21.
Day 3 🔗︎
My plan for Saturday was to dive deep into CPAN.pm. Earlier this year, Andreas discovered a major regression in the “force” pragma for the CPAN shell stemming from my work in Lancaster last year. As an emergency fix, he reverted a dozen or so commits. My goal was to try to recover the reversions, while squashing all the bugs.
Unfortunately, shit happens. The CPAN Testers Metabase (which collects test report submissions) chose that morning to stop working. I discovered that the EC2 instance it was on had gotten wedged, and in the kind of way that EC2’s usual “stop” command wouldn’t even work. So I spent the rest of the morning in EC2 hackery to get Metabase back up and the CPAN Testers reports flowing again.
It was ironic that Metabase died when I was at the hackathon, and yet the hackathon gave me all the round tuits I needed to get it fixed.
With the Metabase repaired, I got back to CPAN.pm. I covered my bases: first I sent Andreas a pull request to revert something else that needed reverting if the reversions were going to stand, then I branched off before the reversions and figured out how to fix the ‘force’ pragma bug directly.
Along the way, I stopped to fix CPAN::Reporter’s prereqs reporting when used with a CPAN.pm that supports recommends/suggests prerequisites.
And throughout the day, I continued the version numbering semantics discussions from the previous evening to test, clarify and refine our understanding.
In the evening, I spent some hours trying and failing to replicate another bug that Andreas had described.
Day 4 🔗︎
Sunday morning started out with a snag — we were unable to get into the Booking.com office and had to work from the hotel. I took advantage of the time to get Andreas to walk me in great detail through the CPAN.pm bug I couldn’t replicate. Thank goodness he keeps copious notes! By the time we got to the hackathon venue, I had a good hypothesis for what I needed to do to replicate it.
With only one afternoon to go, I tried to avoid further discussions and focus on code:
- I implemented metadata fragment conversion in CPAN::Meta::Converter, the lack of which was blocking Leon’s CPAN::Meta::Merge pull request. The I fixed up CPAN::Meta::Merge to use the new feature the way I implemented it. Along the way, I roped Karen into writing some additional tests for fragment conversion and generally sanity checking my code. CPAN::Meta::Merge will make it much easier for distribution packagers to safely and sanely create META files from a mix of detected and provided metadata.
- I cleaned up CPAN::Reporter’s repository, made its tests more efficient and shipped it
- When working on CPAN::Reporter, I wished there was an easy way to run “dzil test” with parallel testing, so I implemented that and sent Ricardo a pull request. (He made it even more general and shipped a new Dist::Zilla within the hour.)
All this got me wondering why dzil build ran so slowly on CPAN::Reporter and someone suggested I try running PERL5OPT=-d:NYTProf dzil build and looking at the flame graph of the result:
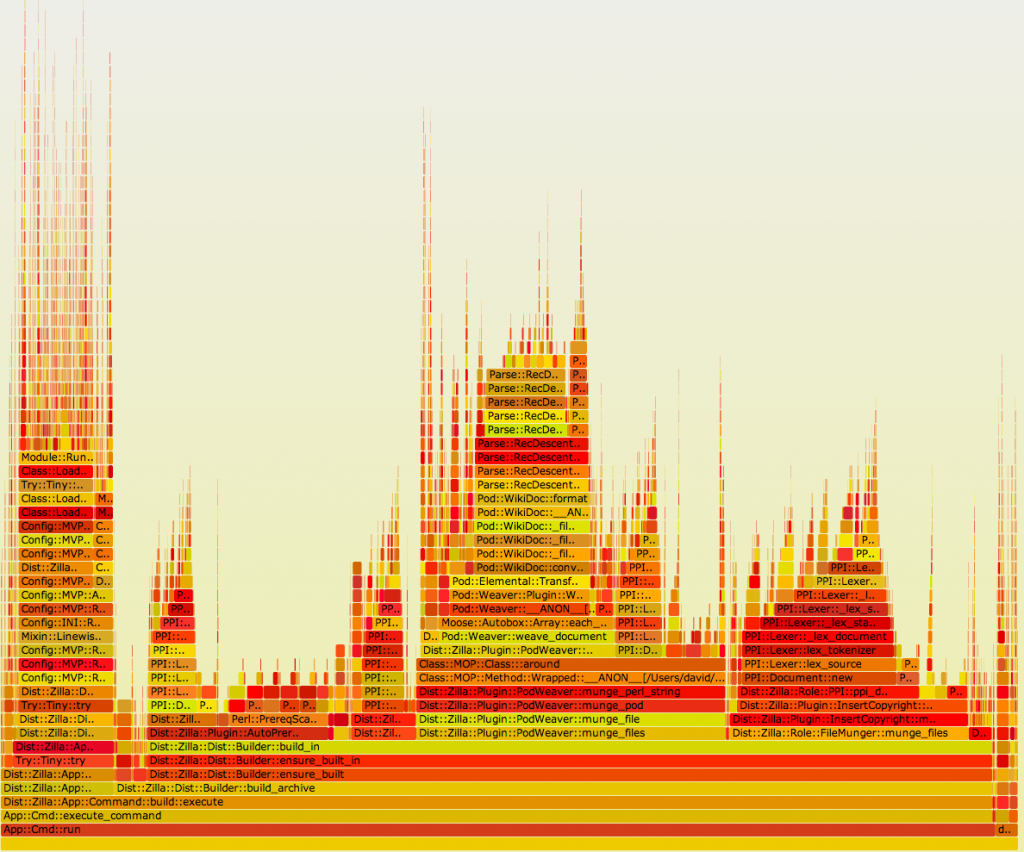
(note: this image is a reconstruction *after* optimization, but it gives you the idea)
Ricardo and a bunch of people looked over my shoulder as we analyzed it and we realized how terribly slow the PerlMinimum plugin was. I also realized my own InsertCopyright plugin wasn’t using the new PPI caching mechanism. So I swapped out PerlMinimum for PerlMinimumFast and patched InsertCopyright. That cut my build time by about 40%.
We also realized that the biggest subroutines were PPI “find” ones, and that inspired Ricardo to think about ways of indexing the PPI DOM for more efficient queries.
I then reviewed the Module::Metadata work that Karen and Graham had been working on and gave it a thumbs up but for some minor comments, and looked at some other pull requests that had been flying around.
We stopped for clean up, group pictures, and headed back to the hotel for dinner.
After dinner, I finally got a chance to finish my CPAN.pm work and had a clean branch that avoided reverting recommends/suggests support, fixed the force pragma bug, avoided the other bug that Andreas showed me, and cherry-picked half a dozen commits that had come in after the reversion (including three of my own from the hackathon).
Day 5 🔗︎
Monday was a travel day. While on the plane, I worked on cleaning up all my CPAN.pm work to be less confusing when I sent it to Andreas.
I also worked on a way of reporting deep dependencies during automated testing, so that Andreas' analysis service can more easily detect when test failures are due to a deep dependency. It’s not done, but I hope to make it a standard part of CPAN testing sometime “soon” (i.e. before next year’s hackathon).
And that was it. I got home, took a shower, talked to my wife, and fell into bed exhausted.
The 2014 Perl QA hackathon was over.